Online augmentation of learned grasp sequence policies for more adaptable and data-efficient in-hand manipulation,
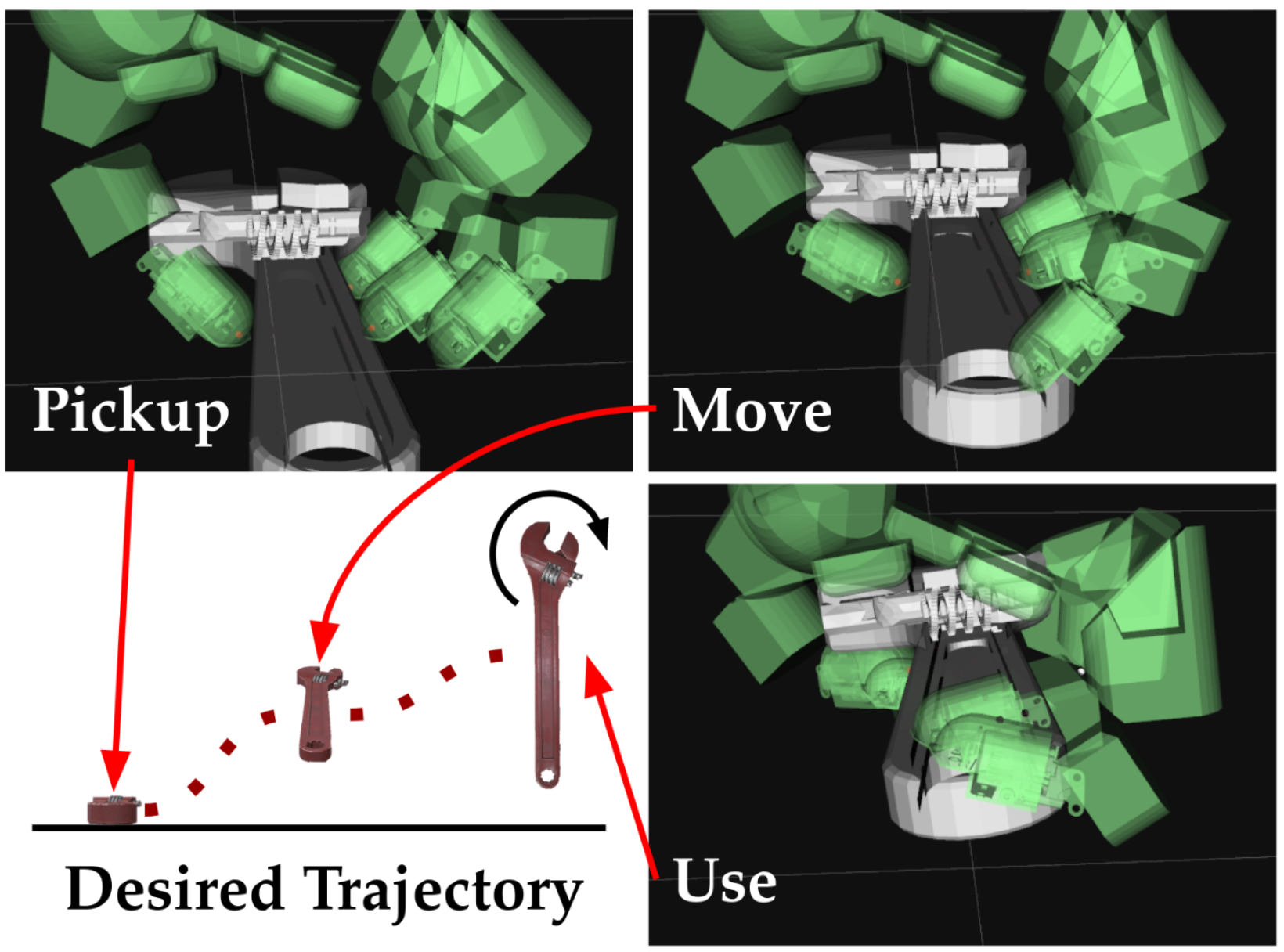
When using a tool, the grasps used for picking it up, reposing, and holding it in a suitable pose for the desired task could be distinct. Therefore, a key challenge for autonomous in-hand tool manipulation is finding a sequence of grasps that facilitates every step of the tool use process while continuously maintaining force closure and stability. Due to the complexity of modeling the contact dynamics, reinforcement learning (RL) techniques can provide a solution in this continuous space subject to highly parameterized physical models. However, these techniques impose a trade-off in adaptability and data efficiency. At test time the tool properties, desired trajectory, and desired application forces could differ substantially from training scenarios. Adapting to this necessitates more data or computationally expensive online policy updates. In this work, we apply the principles of discrete dynamic programming (DP) to augment RL performance with domain knowledge. Specifically, we first design a computationally simple approximation of our environment. We then demonstrate in physical simulation that performing tree searches (i.e., lookaheads) and policy rollouts with this approximation can improve an RL-derived grasp sequence policy with minimal additional online computation. Additionally, we show that pretraining a deep RL network with the DP-derived solution to the discretized problem can speed up policy training.